Airflow¶
Blotout uses airflow for scheduling and monitoring workflows. Airflow is deployed within the blotout cloud which allows organization to have complete access to visualize, manage and monitor pipelines.
Logging in¶
Airflow is available at the /airflow endpoint of Blotout Web application post the deployment step is completed. So if organization name is example and env is prod then the Blotout web application will be hosted at https://example-ui-prod.blotout.io and airflow at https://example-ui-prod.blotout.io/airflow.
Obtaining credentials for airflow¶
- Log in to the AWS console
- Go to the
Secrets Managerservice. Make sure you are in the same region as of your deployment choice. - Following secrets will be available for you. Click on
airflow_password.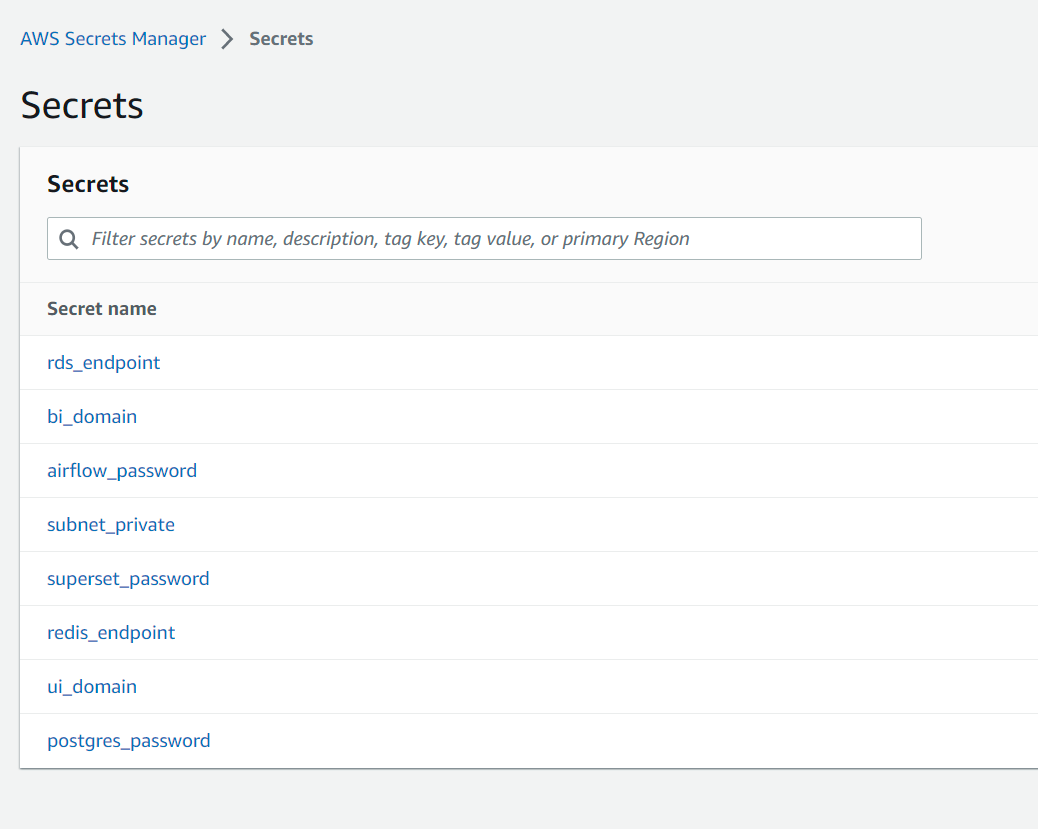
- Click on
Retrieve secret valueto retrieve the password.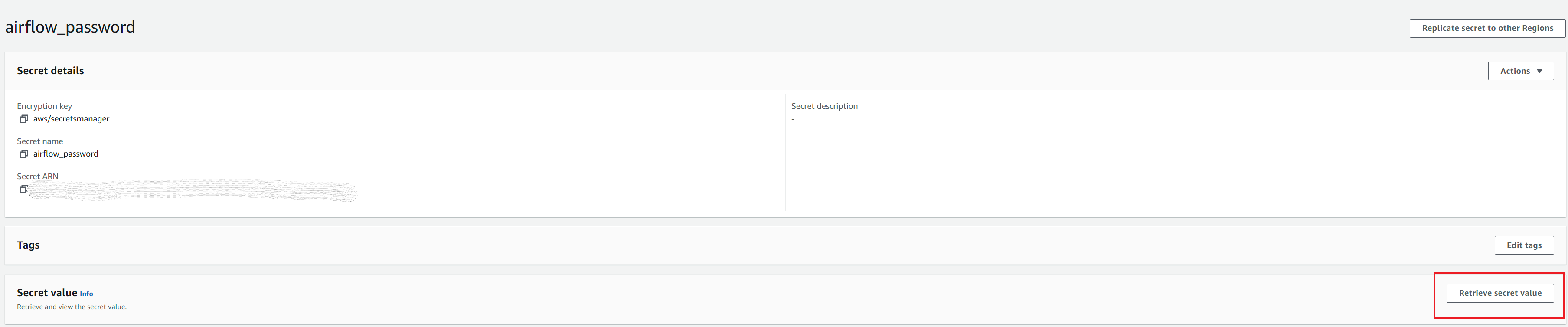
- Log in
airflowwith username asadminand the above password.
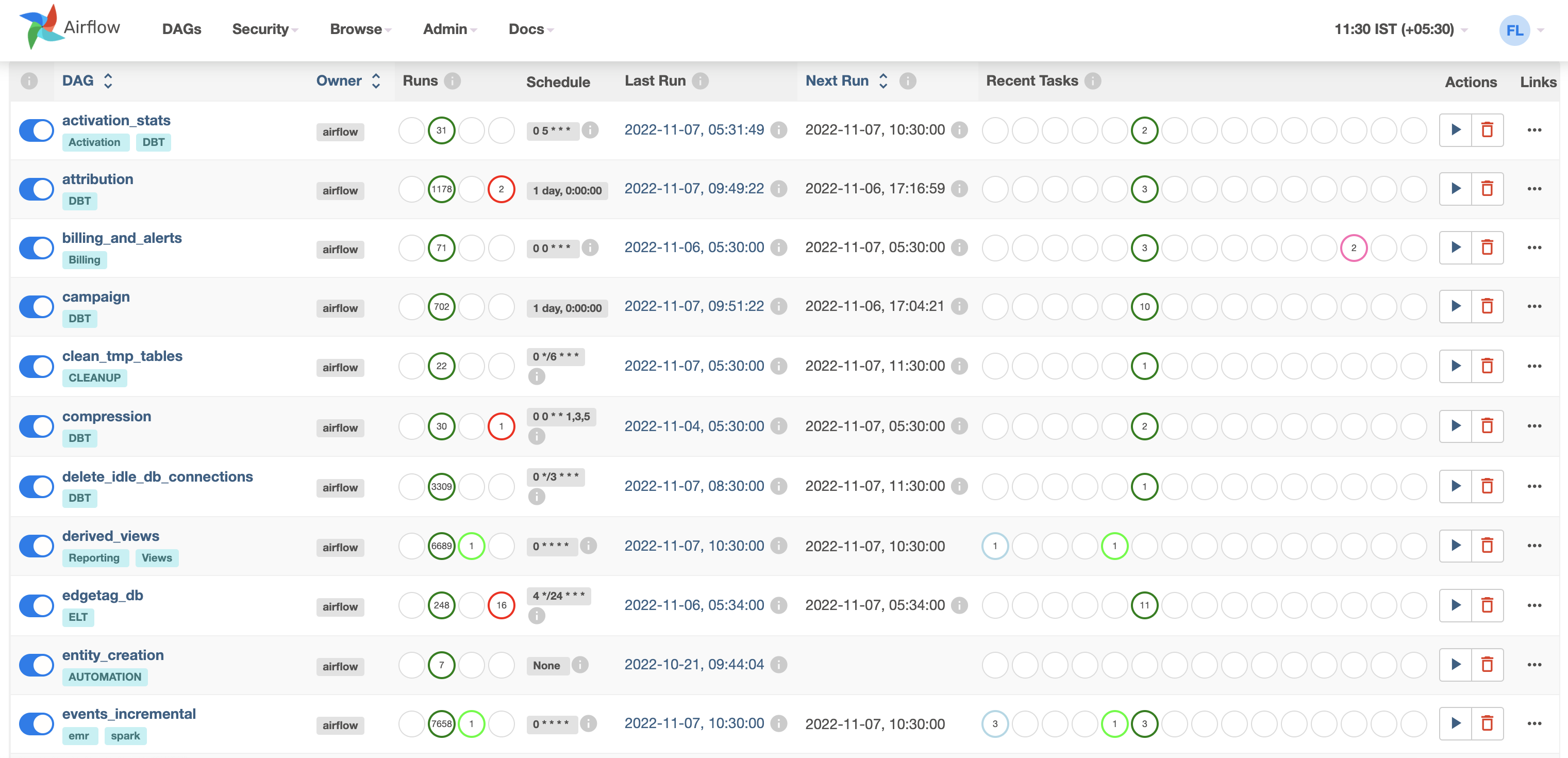
Airflow Jobs¶
Below are the various jobs by default configured in the system
| DAG Name | Category | Description |
|---|---|---|
| one_time_setup | Analytics | Job that trigger at the initial launch of infra for initial setup |
| events_incremental | Analytics | Triggers spark job to process/flatten incremental click stream data and stitch to prepare unified table |
| id_stitching_incremental | ID Graph | ID stitching Job - stitches ID between Online and Offline data and attach with global_user_id |
| events_unified_view | Analytics | Job triggers step by step different DBT models for session, unique_events, transformed/refined models for reporting |
| attribution | Analytics | Job triggers the Campaign DBT model for attribution reporting view |
| campaign | Analytics | Job triggers the Campaign DBT model for campaign reporting view |
| derived_views | Analytics | Job setup the different reporting views (deprecated in 0.21.0) |
| retention | Analytics | Job triggers the Retention DBT model for reporting view |
| compression | Misc | Job to compress small parquet files generated by Spark Job |
| entity_creation | Misc | Dynamic Job (enables On Shopify ELT pipeline creation) - to auto sync predefined entities like funnel, segment etc. |
| cleanup_temp_tables | Misc | Job for clean up temp tables created in Data Lake |
| delete_idle_db_connections | Misc | Periodical Job releases the idle Database connection |
| billing | Misc | Monthly Job which trigger the Hardware Cost to configured email address |
| activation_stats | Activation | Job to reconcile the activation pipeline stats and maintain the daily sync records per channel |
| scan_report_runs_and_send_email | Superset | Automation job to schedule dashboards and send on email |
| sync_superset_dashboard | Superset | Automation job to auto sync newly added charts/dashboards etc. |
| sync_superset_tables | Superset | Automation job to auto sync all the tables available in data lake |
Airflow variables¶
Below are the variables that are present in airflow. TO check the variables click on Admin and then Variables. To know more, check Manage Airflow Variables
| Name | Value (example) | Description |
|---|---|---|
| AIRBYTE_URL | https://ORGNAME-ui-ENV.blotout.io | Airbyte URL |
| AIRFLOW_DAG_FAILED_EMAIL | alert@blotout.io | |
| AIRFLOW_START_DATE | 1977-10-01 00:00:00 | Assumed start time for airflow cron jobs |
| AWS_REGION | us-west-2 | AWS region of deployment |
| COMPUTATION_WINDOW | 90 | |
| EMR_EC2_INSTANCE_TYPE | m4.large | EC2 instance type for EMR |
| EVENTS_INCREMENTAL_SCHEDULE_INTERVAL | 0 * * * * | Cron time for click stream data processing |
| ID_STITCHING_INCREMENTAL_SCHEDULE_INTERVAL | 0 */4 * * * | Cron time for ID Stitching Job |
| PRIVATE_SUBNET | subnet-048ee3a00944bc2e0 | Subnet ID in which infrastructure is running |
| SCHEDULE_INTERVAL_DELETE_IDLE_CONNECTIONS | 0 */3 * * * | Cron time for job to delete idle db connections |
| SUPERSET_BASE_URL | https://ORGNAME-ui-ENV.blotout.io | Superset URL |
| SUPERSET_PASSWORD | Superset password | |
| SUPERSET_USERNAME | superset username | |
| SUPERSET_USER_EMAIL | superset email | |
| TAG_DBT_ANALYTICS | 0.20.0 | DBT Module Docker tag |
| TAG_DBT_CODE_GENERATOR | 0.20.0 | DBT Module Docker tag |
| TAG_DBT_REVERSE_EL | 0.20.0 | Reverse EL (Activation) Docker tag |
| TAG_SUPERSET_AUTOMATION | 0.20.0 | Superset Automation Docker tag |
| USER_REPORTING_SCHEDULE_INTERVAL | */30 * * * * | Cron Time for Superset Dashboard automation |
ELT Pipeline¶
As the user adds new ELT pipeline, Airflow automatically picks that up and create the respective Airflow ELT pipeline for the same.
Activation Pipeline¶
As the user adds new Activation channel like Klaviyo, Facebook Audience etc. for Audience sync, Airflow automatically picks that up and create the respective Airflow ELT pipeline for the same.